No items found.
By Jorge Vasquez
REST APIs are fundamental for modern cloud-based applications, facilitating communication between various systems and services. Given the importance of availability, scalability, and performance in these applications, the choice of programming language and libraries for API implementation is crucial: A suboptimal decision can negatively impact these key metrics. At the same time, we should reduce the probability of introducing bugs in the development phase, making illegal states impossible to represent in our source code.
So, in this article we will explore some options the Scala 3 ecosystem gives us for the job, leveraging the power of:
As stated in the ZIO documentation page: ZIO HTTP is a Scala library for building http apps. It is powered by ZIO and Netty and aims at being the defacto solution for writing, highly scalable and performant web applications using idiomatic Scala.
Because ZIO HTTP is built on top of ZIO, it inherits all of its great features, namely:
Besides all of those features, ZIO HTTP supports some other specific ones:
ZIO HTTP offers two APIs which developers can choose from in order to implement HTTP applications:
When you work with the Routes API, you have to define your HTTP API as a routing table, where each route is a mapping from HTTP method and path to a request handler. For instance, if you wanted to define an API for a shopping cart application, you would have to do it like this:
import zio.http.*
val routes =
Routes(
Method.POST / "cart" / uuid("userId") ->
handler(handleInitializeCart _),
Method.POST / "cart" / uuid("userId") / "item" ->
handler(handleAddItem _),
Method.DELETE / "cart" / uuid("userId") / "item" / uuid("itemId") ->
handler(handleRemoveItem _),
Method.PUT / "cart" / uuid("userId") / "item" / uuid("itemId") ->
handler(handleUpdateItem _),
Method.GET / "cart" / uuid("userId") ->
handler(handleGetCartContents _)
)
So, for each case, you can see we are mapping a route (which contains an HTTP method like GET, POST, PUT, DELETE and a path with variables like userId) to a Handler, which is a ZIO HTTP data type that can be constructed in several ways, e.g. from a function that returns a ZIO effect, like handleAddItem:
def handleAddItem(userId: UUID, req: Request): URIO[CartService, Response] =
for
_ <- ZIO.logInfo("Adding item to cart")
// We have to manually decode the body as JSON, handling errors
body <- req.body.asString.orDie
item <- ZIO.fromEither(body.fromJson[Item]).orDieWith(RuntimeException(_))
items0 <- CartService.addItem(userId, item)
// We have to manually obtain and validate headers from the `Request` object
allItems = req.headers.get("X-ALL-ITEMS")
items <- allItems match
case Some(allItems) =>
ZIO.attempt(allItems.toBoolean).orDie.map {
case true => items0
case false => Items.empty + item
}
case None => ZIO.succeed(Items.empty + item)
yield Response.json(items.toJson) // We have to manually encode the Response as JSON
So, handleAddItem:
As you can see, working with the Routes API involves manual decoding of headers, query parameters and request body; it also involves manual encoding of responses. This is why we say the Routes API is low-level and imperative. I won’t go into more detail about this here, but you can learn more from these sources:
When you work with the Endpoints API, firstly you need to describe each one of the endpoints of your HTTP API. This description is at a high level and does not include the actual implementation for the endpoint. It contains:
For every property, you can include documentation that will be used when generating OpenAPI docs or a ZIO CLI application from your Endpoint definition. We will see how easy it is to generate OpenAPI docs and serve them as a Swagger page in the full example we will work in a below section; and if you are curious about how to generate a ZIO CLI application, you can take a look at this link:
Here we have an example of how we would define an Endpoint for adding an Item in our shopping cart example:
val addItem =
Endpoint(Method.POST / "cart" / uuid("userId") / "item")
.in[Item](Doc.p("Item to add"))
.header[Boolean]("X-ALL-ITEMS", Doc.p("Indicate whether to return all items or just the new one"))
.out[Items](Doc.p("The operation result")) ?? Doc.p("Add an item to a user's cart")
The addItem Endpoint says several things:
Once you have all your Endpoints defined, you can transform them to ZIO HTTP Routes like this:
val routes =
Routes(
initializeCart.implement(handler(handleInitializeCart _)),
addItem.implement(handler(handleAddItem _)),
removeItem.implement(handler(handleRemoveItem _)),
updateItem.implement(handler(handleUpdateItem _)),
getCartContents.implement(handler(handleGetCartContents _))
)
So basically each Endpoint has to be implemented by a given Handler. Let’s see how handleAddItem looks:
def handleAddItem(
userId: UserId,
allItems: Option[Boolean],
item: Item
): URIO[CartService, Items] =
for
_ <- ZIO.logInfo("Adding item to cart")
items0 <- CartService.addItem(userId, item)
items = allItems match
case Some(true) => items0
case _ => Items.empty + item
yield items
If we compare this version of the Handler with the previous one we had when working with the Routes API, we see some important differences:
All of this means that, when working with the Endpoints API, we don’t need to manually decode Requests and encode Responses because that’s automatically handled by ZIO HTTP for us (thanks to the integration with ZIO Schema), and we can work just with our domain models!
I won’t go deeper here, but If you want to learn more, you can take a look at the following links:
Magnum is a database client for Scala 3, with the following characteristics:
We will go into details of how this library works in the full example we will work on soon. Also, if you want to learn more about it you can watch:
Iron is a lightweight library for refined types in Scala 3, it enables attaching constraints to types, to enforce properties and forbid invalid values. In this sense, it’s similar to the refined library, but in my personal opinion the syntax is nicer. Other related libraries for Scala 3 are neotype and ZIO Prelude, which offer similar functionality but the main difference is that constraints are written at the value level, instead of the type level. As a side note, if you are curious about how Newtypes work in ZIO Prelude, you can watch the recording of this presentation I’ve given at Functional Scala 2022:
Thanks to Iron you can:
We will see this library in action in the next section. Also here’s a link to a presentation where you can learn more:
It’s time to see how we can use ZIO HTTP, Magnum and Iron together to implement a REST API. As an example we will implement an API which offers typical CRUD operations for managing departments inside a company, employees and their phone numbers. Data will be stored in a PostgreSQL database, and because this is just an example we will be using Testcontainers to start it inside a container.
The following diagram shows the database schema:
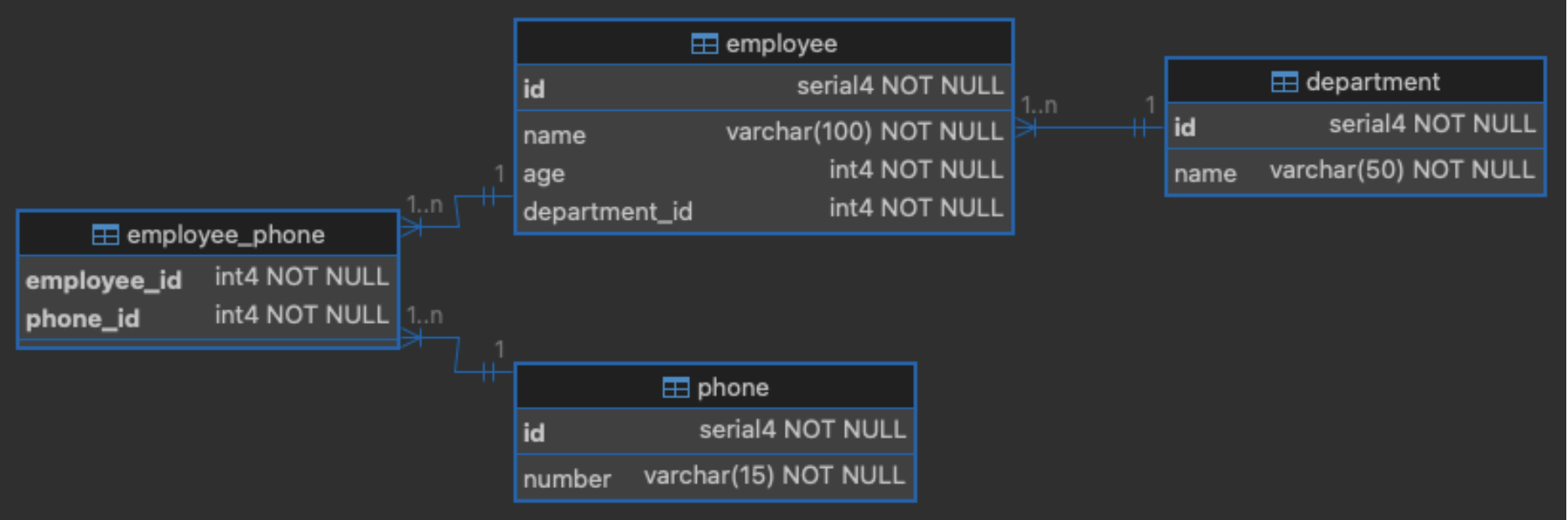
Before starting with the implementation, let’s add the library dependencies we will need to our build.sbt file:
lazy val root = (project in file("."))
.settings(
name := "zio-backend-example",
scalacOptions ++= Seq(
"-Wunused:imports"
),
libraryDependencies ++= Seq(
// ZIO HTTP
"dev.zio" %% "zio-http" % "3.2.0",
// Database
"com.augustnagro" %% "magnumzio" % "2.0.0-M1",
"org.postgresql" % "postgresql" % "42.7.5",
"org.testcontainers" % "testcontainers" % "1.20.4",
"org.testcontainers" % "postgresql" % "1.20.4",
"com.zaxxer" % "HikariCP" % "6.2.1"
// Iron
"io.github.iltotore" %% "iron" % "3.0.0",
// Logging
"dev.zio" %% "zio-logging-jul-bridge" % "2.4.0"
)
)
You can see the libraries we are adding include:
For reference, you can see the complete implementation of the application in this GitHub repository.
To implement the database logic in our application, there are some steps we have to follow:
Let’s create a class representing the employee table:
package com.example.tables
import com.augustnagro.magnum.magzio.*
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class Employee(
@Id id: Int,
name: String,
age: Int,
departmentId: Int
) derives DbCodecSeveral things need to be explained here:
Now we can do something similar for the rest of the tables:
package com.example.tables
import com.augustnagro.magnum.magzio.*
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class Department(
@Id id: Int,
name: String
) derives DbCodec
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class Phone(
@Id id: Int,
number: String
) derives DbCodec
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class EmployeePhone(
employeeId: Int,
phoneId: Int
) derives DbCodec
The only important thing to notice here is that EmployeePhone has no @Id field, because the corresponding table does not have an auto-generated ID column.
Let’s define some domain models now. There’s nothing special about this, just simple Scala case classes:
package com.example.domain
final case class Department(name: String)
final case class Employee(name: String, age: Int, departmentId: Int)
final case class Phone(number: String)
You can see they are very similar to our entity classes, the only difference is they do not contain ID columns because those will be generated by the database, not by our application.
We can also add some convenience methods to our entity classes to convert to/from domain. For instance:
package com.example.tables
import com.augustnagro.magnum.magzio.*
import com.example.domain
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class Employee(
@Id id: Int,
name: String,
age: Int,
departmentId: Int
) derives DbCodec:
val toDomain = domain.Employee(name, age, departmentId)
object Employee:
def fromDomain(employeeId: Int, employee: domain.Employee): Employee =
Employee(employeeId, employee.name, employee.age, employee.departmentId)
The next step will be defining some repositories that will interact with the database using the Magnum library and hiding implementation details to the rest of the application.
Let’s define the interface of EmployeeRepository:
package com.example.repository
import com.example.domain.Employee
import zio.*
trait EmployeeRepository:
def create(employee: Employee): UIO[Int]
def retrieve(employeeId: Int): UIO[Option[Employee]]
def retrieveAll: UIO[Vector[Employee]]
def update(employeeId: Int, employee: Employee): UIO[Unit]
def delete(employeeId: Int): UIO[Unit]And here’s the skeleton for the implementation, following the ZIO service pattern:
package com.example.repository
import com.augustnagro.magnum.magzio.*
import zio.*
final case class EmployeeRepositoryLive() with EmployeeRepository:
override def create(employee: Employee): UIO[Int] = ???
override def retrieve(employeeId: Int): UIO[Option[Employee]] = ???
override val retrieveAll: UIO[Vector[Employee]] = ???
override def update(employeeId: Int, employee: Employee): UIO[Unit] = ???
override def delete(employeeId: Int): UIO[Unit] = ???
object EmployeeRepositoryLive:
val layer: URLayer[Transactor, EmployeeRepository] =
ZLayer.fromFunction(EmployeeRepositoryLive(_))Nothing special so far. Now, if we want EmployeeRepositoryLive to use the power of Magnum’s auto-derived CRUD operations (you can take a look to the whole list of operations here), we will need to extend the Repo[EC, E, ID] class, where:
By the way, there’s also an ImmutableRepo[EC, E, ID] class that you can use if only read operations are needed..
We will also need a Transactor, which provides two methods:
So here we have the complete implementation of EmployeeRepositoryLive:
package com.example.repository
import com.augustnagro.magnum.magzio.*
import com.example.domain.Employee
import com.example.tables
import zio.*
final case class EmployeeRepositoryLive(xa: Transactor)
extends Repo[Employee, tables.Employee, Int]
with EmployeeRepository:
override def create(employee: Employee): UIO[Int] =
xa.transact {
insertReturning(employee).id
}.orDie
override def retrieve(employeeId: Int): UIO[Option[Employee]] =
xa.transact {
findById(employeeId).map(_.toDomain)
}.orDie
override val retrieveAll: UIO[Vector[Employee]] =
xa.transact {
findAll.map(_.toDomain)
}.orDie
override def update(employeeId: Int, employee: Employee): UIO[Unit] =
xa.transact {
update(tables.Employee.fromDomain(employeeId, employee))
}.orDie
override def delete(employeeId: Int): UIO[Unit] =
xa.transact {
deleteById(employeeId)
}.orDie
Let’s see in detail how create is implemented so you understand the basic idea, the other methods are implemented similarly:
override def create(employee: Employee): UIO[Int] =
xa.transact {
insertReturning(employee).id
}.orDie
You can see we are calling the insertReturning method that comes from the Repo class, which:
The only way we can obtain the implicit DbCon that insertReturning requires is by calling it inside:
Notice that insertReturning is not a pure method, it does not return a ZIO effect so if database failures happen they are just thrown as exceptions. This same pattern applies to all methods inherited from Repo and that’s by design: the idea is that you can use imperative style inside xa.connect or xa.transact, and these encapsulate everything inside ZIO. For our example, we are calling ZIO#orDie on the returned effect, so that we just let the calling fiber die in case of database exceptions.
The implementation of EmployeePhoneRepository will be similar but with some important details to notice:
package com.example.repository
import com.augustnagro.magnum.magzio.*
import com.example.domain.Phone
import com.example.tables
import zio.*
trait EmployeePhoneRepository:
def addPhoneToEmployee(phoneId: Int, employeeId: Int): UIO[Unit]
def retrieveEmployeePhones(employeeId: Int): UIO[Vector[Phone]]
def removePhoneFromEmployee(phoneId: Int, employeeId: Int): UIO[Unit]
final case class EmployeePhoneRepositoryLive(xa: Transactor)
extends Repo[tables.EmployeePhone, tables.EmployeePhone, Null]
with EmployeePhoneRepository:
override def addPhoneToEmployee(phoneId: Int, employeeId: Int): UIO[Unit] =
xa.transact {
insert(tables.EmployeePhone(employeeId, phoneId))
}.orDie
override def retrieveEmployeePhones(employeeId: Int): UIO[Vector[Phone]] =
xa.transact {
val statement =
sql"""
SELECT ${tables.Phone.table.all}
FROM ${tables.Phone.table}
INNER JOIN ${tables.EmployeePhone.table} ON ${tables.EmployeePhone.table.phoneId} = ${tables.Phone.table.id}
WHERE ${tables.EmployeePhone.table.employeeId} = $employeeId
"""
statement.query[tables.Phone].run().map(_.toDomain)
}.orDie
override def removePhoneFromEmployee(phoneId: Int, employeeId: Int): UIO[Unit] =
xa.transact {
delete(tables.EmployeePhone(employeeId, phoneId))
}.orDie
object EmployeePhoneRepositoryLive:
val layer: URLayer[Transactor, EmployeePhoneRepository] =
ZLayer.fromFunction(EmployeePhoneRepositoryLive(_))
The first thing to notice is that EmployeePhoneRepository extends Repo[tables.EmployeePhone, tables.EmployeePhone, Null], which means:
Next, addPhoneToEmployee and removePhoneFromEmployee are implemented in the same way as we explained above for EmployeeRepository so no additional explanation is needed. However, retrieveEmployeePhones is implemented differently so let’s analyze it:
override def retrieveEmployeePhones(employeeId: Int): UIO[Vector[Phone]] =
xa.transact {
val statement =
sql"""
SELECT p.id, p.number
FROM phone p
INNER JOIN employee_phone ep ON ep.phone_id = p.id
WHERE ep.employee_id = $employeeId
"""
statement.query[tables.Phone].run().map(_.toDomain)
}.orDie
Inside the xa.transact block you can see we are defining a SQL query by hand, instead of using one of the methods inherited from the Repo class. The reason is that we need to join the employee table with the employee_phone table, and the Repo class does not offer a direct way to do that. The good news is that writing custom SQL queries works pretty much the same as in other libraries like doobie: We have a sql string interpolator that we can use to create Frags, where we can interpolate values without the risk of SQL-injection attacks.
Once you have a Frag, you can turn it into a Query by calling the Frag#query method, where you must indicate the expected entity class for each row (in this case tables.Phone). Once you have a Query, you can run it using the Query#run method, which:
And that’s how you can write custom SQL queries in Magnum! There’s an important problem though: retrieveEmployeePhones is not future-proof because if at some moment we change a column or table name it’s very possible that we forget to update the custom SQL query, and we will only know it at runtime. Also, it’s not nice having to write SELECT col1, col2, col3…, especially for large tables. To help with this, Magnum offers a TableInfo[EC, E, ID] class that we can define in our entities’ companion objects, like this:
package com.example.tables
import com.augustnagro.magnum.magzio.*
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class EmployeePhone(
employeeId: Int,
phoneId: Int
) derives DbCodec
object EmployeePhone:
val table = TableInfo[EmployeePhone, EmployeePhone, Null]
The type parameters in TableInfo represent the same information as in the Repo class, and we can do something similar for other entities.
Now that we have TableInfo, we can refactor our custom SQL query like this:
override def retrieveEmployeePhones(employeeId: Int): UIO[Vector[Phone]] =
xa.transact {
val statement =
sql"""
SELECT ${tables.Phone.table.all}
FROM ${tables.Phone.table}
INNER JOIN ${tables.EmployeePhone.table}
ON ${tables.EmployeePhone.table.phoneId} = ${tables.Phone.table.id}
WHERE ${tables.EmployeePhone.table.employeeId} = $employeeId
"""
statement.query[tables.Phone].run().map(_.toDomain)
}.orDie
So now we don’t need to manually write every column when doing a SELECT, we can just do SELECT ${tables.Phone.table.all}, and if we change a column or table name the compiler will let us know.
The implementation of DepartmentRepository will be like this:
package com.example.repository
import com.augustnagro.magnum.magzio.*
import com.example.domain.Department
import com.example.tables
import zio.*
trait DepartmentRepository:
def create(department: Department): UIO[Int]
def retrieve(departmentId: Int): UIO[Option[Department]]
def retrieveByName(departmentName: String): UIO[Option[Department]]
def retrieveAll: UIO[Vector[Department]]
def update(departmentId: Int, department: Department): UIO[Unit]
def delete(departmentId: Int): UIO[Unit]
final case class DepartmentRepositoryLive(xa: Transactor)
extends Repo[Department, tables.Department, Int]
with DepartmentRepository:
override def create(department: Department): UIO[Int] =
xa.transact {
insertReturning(department).id
}.orDie
override def retrieve(departmentId: Int): UIO[Option[Department]] =
xa.transact {
findById(departmentId).map(_.toDomain)
}.orDie
override def retrieveByName(departmentName: String): UIO[Option[Department]] =
xa.transact {
val spec = Spec[tables.Department].where(sql"${tables.Department.table.name} = $departmentName")
findAll(spec).headOption.map(_.toDomain)
}.orDie
override val retrieveAll: UIO[Vector[Department]] =
xa.transact {
findAll.map(_.toDomain)
}.orDie
override def update(departmentId: Int, department: Department): UIO[Unit] =
xa.transact {
update(tables.Department.fromDomain(departmentId, department))
}.orDie
override def delete(departmentId: Int): UIO[Unit] =
xa.transact {
deleteById(departmentId)
}.orDie
object DepartmentRepositoryLive:
val layer: URLayer[Transactor, DepartmentRepository] =
ZLayer.fromFunction(DepartmentRepositoryLive(_))
All the methods are using the inherited ones from the Repo class, so the implementation is straightforward, however the retrieveByName method introduces something new:
override def retrieveByName(departmentName: String): UIO[Option[Department]] =
xa.transact {
val spec =
Spec[tables.Department]
.where(sql"${tables.Department.table.name} = $departmentName")
findAll(spec).headOption.map(_.toDomain)
}.orDie
Here you can see we are trying to retrieve a department by the given name, for that we are using the findAll from the Repo class, which can be provided with an Spec[E] to filter and paginate the obtained results. For this case:
PhoneRepository is very similar to DepartmentRepository, so if you are curious you can check its implementation in the GitHub repo.
We will have some Services that will use the Repositories we have written in the previous section:
There’s nothing special at this level, all the implementations will be just about ZIO! Remember the Repositories isolate all the Magnum implementation details. So, I will not go through all the details here. Let’s just see EmployeePhoneService as an example:
package com.example.service
import com.example.domain.Phone
import com.example.error.AppError
import com.example.error.AppError.*
import com.example.repository.{ EmployeePhoneRepository, EmployeeRepository, PhoneRepository }
import zio.*
trait EmployeePhoneService:
def addPhoneToEmployee(phoneId: Int, employeeId: Int): IO[AppError, Unit]
def retrieveEmployeePhones(employeeId: Int): IO[EmployeeNotFound, Vector[Phone]]
def removePhoneFromEmployee(phoneId: Int, employeeId: Int): IO[AppError, Unit]
final case class EmployeePhoneServiceLive(
employeePhoneRepository: EmployeePhoneRepository,
employeeRepository: EmployeeRepository,
phoneRepository: PhoneRepository
) extends EmployeePhoneService:
override def addPhoneToEmployee(phoneId: Int, employeeId: Int): IO[AppError, Unit] =
phoneRepository.retrieve(phoneId).someOrFail(PhoneNotFound)
*> employeeRepository.retrieve(employeeId).someOrFail(EmployeeNotFound)
*> employeePhoneRepository.addPhoneToEmployee(phoneId, employeeId)
override def retrieveEmployeePhones(employeeId: Int): IO[EmployeeNotFound, Vector[Phone]] =
employeeRepository.retrieve(employeeId).someOrFail(EmployeeNotFound)
*> employeePhoneRepository.retrieveEmployeePhones(employeeId)
override def removePhoneFromEmployee(phoneId: Int, employeeId: Int): IO[AppError, Unit] =
phoneRepository.retrieve(phoneId).someOrFail(PhoneNotFound)
*> employeeRepository.retrieve(employeeId).someOrFail(EmployeeNotFound)
*> employeePhoneRepository.removePhoneFromEmployee(phoneId, employeeId)
object EmployeePhoneServiceLive:
val layer: URLayer[
EmployeePhoneRepository & EmployeeRepository & PhoneRepository,
EmployeePhoneService
] = ZLayer.fromFunction(EmployeePhoneServiceLive(_, _, _))
You can see methods can fail with an AppError, which is defined like this:
package com.example.error
sealed trait AppError
object AppError:
case object DepartmentNotFound extends AppError
type DepartmentNotFound = DepartmentNotFound.type
case object DepartmentAlreadyExists extends AppError
type DepartmentAlreadyExists = DepartmentAlreadyExists.type
case object EmployeeNotFound extends AppError
type EmployeeNotFound = EmployeeNotFound.type
case object PhoneNotFound extends AppError
type PhoneNotFound = PhoneNotFound.type
case object PhoneAlreadyExists extends AppError
type PhoneAlreadyExists = PhoneAlreadyExists.type
If you are wondering why I’m using a sealed trait instead of an enum for AppError, just know that I’ve done that for a good reason that will be explained later.
Now that we have implemented our Services, we are ready to define our API routes. In order to do that, we will be using the ZIO HTTP Endpoints API.
Our server will be exposing the following endpoints:
We will see now how to create a trait containing Endpoints for managing employees. The rest of the endpoints follow the same logic so we will not discuss them here.
Let’s see how we would define the Endpoint for updating an Employee:
import zio.http.*
import zio.http.codec.*
import zio.http.endpoint.Endpoint
trait EmployeeEndpoints:
val updateEmployee =
Endpoint(Method.PUT / "employee" / int("id"))
.in[Employee](Doc.p("Employee to be updated"))
.out[Unit]
.outError[EmployeeNotFound](Status.NotFound, Doc.p("The employee was not found"))
?? Doc.p("Update the employee with the given `id`")
Several things are happening here, so let’s explain them in detail:
package com.example.domain
import zio.schema.*
final case class Department(name: String) derives Schema
package com.example.error
import zio.schema.*
sealed trait AppError derives Schema
object AppError:
case object DepartmentNotFound extends AppError derives Schema
type DepartmentNotFound = DepartmentNotFound.type
case object DepartmentAlreadyExists extends AppError derives Schema
type DepartmentAlreadyExists = DepartmentAlreadyExists.type
case object EmployeeNotFound extends AppError derives Schema
type EmployeeNotFound = EmployeeNotFound.type
case object PhoneNotFound extends AppError derives Schema
type PhoneNotFound = PhoneNotFound.type
case object PhoneAlreadyExists extends AppError derives Schema
type PhoneAlreadyExists = PhoneAlreadyExists.type
Here you can see why I’ve decided to use a sealed trait instead of an enum for AppError: that way I can use derives Schema for each error case.
And what does the updateEmployeee type tell us? We have:
Endpoint[Int, (Int, Employee), EmployeeNotFound, Unit, AuthType.None]
Now that you know how to implement updateDepartment, here you have all of the Endpoints for managing employees, which are implemented in a similar way:
package com.example.api.endpoint
import com.example.domain.*
import com.example.error.AppError.{ DepartmentNotFound, EmployeeNotFound }
import zio.http.*
import zio.http.codec.*
import zio.http.endpoint.Endpoint
trait EmployeeEndpoints:
val createEmployee =
Endpoint(Method.POST / "employee")
.in[Employee](Doc.p("Employee to be created"))
.out[Int](Doc.p("ID of the created employee"))
.outError[DepartmentNotFound](Status.NotFound, Doc.p("The employee's department was not found"))
?? Doc.p("Create a new employee")
val getEmployees =
Endpoint(Method.GET / "employee")
.out[Vector[Employee]](Doc.p("List of employees")) ?? Doc.p("Obtain a list of employees")
val getEmployeeById =
Endpoint(Method.GET / "employee" / int("id"))
.out[Employee](Doc.p("Employee"))
.outError[EmployeeNotFound](Status.NotFound, Doc.p("The employee was not found"))
?? Doc.p("Obtain the employee with the given `id`")
val updateEmployee =
Endpoint(Method.PUT / "employee" / int("id"))
.in[Employee](Doc.p("Employee to be updated"))
.out[Unit]
.outError[EmployeeNotFound](Status.NotFound, Doc.p("The employee was not found"))
?? Doc.p("Update the employee with the given `id`")
val deleteEmployee =
Endpoint(Method.DELETE / "employee" / int("id"))
.out[Unit]
?? Doc.p("Delete the employee with the given `id`")
Now that we have defined our Endpoints, which are just high level descriptions, we need to actually implement them, which means defining the Routes of our application like this:
package com.example.api
import com.example.api.endpoint.*
import com.example.api.handler.*
import com.example.domain.*
import com.example.service.*
import zio.*
import zio.http.*
import zio.http.endpoint.openapi.*
trait Router
extends DepartmentEndpoints
with DepartmentHandlers
with EmployeeEndpoints
with EmployeeHandlers
with PhoneEndpoints
with PhoneHandlers
with EmployeePhoneEndpoints
with EmployeePhoneHandlers:
val routes: Routes[
DepartmentService & EmployeeService & PhoneService & EmployeePhoneService,
Nothing
] =
Routes(
createDepartment.implementHandler(handler(createDepartmentHandler)),
getDepartments.implementHandler(handler(getDepartmentsHandler)),
getDepartmentById.implementHandler(handler(getDepartmentHandler)),
updateDepartment.implementHandler(handler(updateDepartmentHandler)),
deleteDepartment.implementHandler(handler(deleteDepartmentHandler)),
createEmployee.implementHandler(handler(createEmployeeHandler)),
getEmployees.implementHandler(handler(getEmployeesHandler)),
getEmployeeById.implementHandler(handler(getEmployeeHandler)),
updateEmployee.implementHandler(handler(updateEmployeeHandler)),
deleteEmployee.implementHandler(handler(deleteEmployeeHandler)),
createPhone.implementHandler(handler(createPhoneHandler)),
getPhoneById.implementHandler(handler(getPhoneHandler)),
updatePhone.implementHandler(handler(updatePhoneHandler)),
deletePhone.implementHandler(handler(deletePhoneHandler)),
addPhoneToEmployee.implementHandler(handler(addPhoneToEmployeeHandler)),
retrieveEmployeePhones.implementHandler(handler(retrieveEmployeePhonesHandler)),
removePhoneFromEmployee.implementHandler(handler(removePhoneFromEmployeeHandler))
)
So, we have a Router trait that:
Notice that to implement an Endpoint we have to call the Endpoint#implementHandler method, which expects a Handler[-R, +Err, -In, +Out], where the error, input and output type of the Handler have to match the corresponding types of the Endpoint. Also realize that Endpoint#implementHandler returns a Route[-Env, +Err].
Now, Handler has several constructors like Handler.fromZIO, Handler.fromFunction, Handler.fromFunctionZIO, etc. that you can use. However the easiest way is to use the handler smart constructor, that can take several input types like a ZIO effect, a pure function, a function returning a ZIO effect, etc. and that’s what we are doing here.
For instance, you can see:
Both Handlers are defined inside the DepartmentHandlers trait like this:
package com.example.api.handler
import com.example.domain.Department
import com.example.error.AppError.{ DepartmentAlreadyExists, DepartmentNotFound }
import com.example.service.DepartmentService
import zio.*
trait DepartmentHandlers:
def createDepartmentHandler(
department: Department
): ZIO[DepartmentService, DepartmentAlreadyExists, Int] =
ZIO.serviceWithZIO[DepartmentService](_.create(department))
val getDepartmentsHandler: URIO[DepartmentService, Vector[Department]] =
ZIO.serviceWithZIO[DepartmentService](_.retrieveAll)
So, createDepartmentHandler is a function that receives a Department as input and returns a ZIO effect. We needed a function because the corresponding createDepartment expects the Department input.
On the other hand, getDepartmentsHandler is not a function, but just a ZIO effect. That makes sense because the corresponding getDepartments endpoint expects no inputs.
And what happens when an Endpoint expects multiple inputs, like in the case of addPhoneToEmployee? Well, no problem at all! Just define your handler as a function with two inputs!
trait EmployeePhoneHandlers:
def addPhoneToEmployeeHandler(
phoneId: Int,
employeeId: Int
): ZIO[EmployeePhoneService, AppError, Unit] =
ZIO.serviceWithZIO[EmployeePhoneService](_.addPhoneToEmployee(phoneId, employeeId))
That’s how you implement Endpoints, by calling Endpoint#implementHandler on them. That’s the most general way, but you have to know that there are other more specific Endpoint#implement* methods you could use as well, like this:
createDepartment.implement(createDepartmentHandler)
Here we are calling Endpoint#implement which expects a function returning a ZIO effect.
Generating the OpenAPI docs for our endpoints and serving them through SwaggerUI is a piece of cake. Let’s add a swaggerRoutes variable to our Router:
package com.example.api
import zio.http.endpoint.openapi.*
trait Router
extends DepartmentEndpoints
with DepartmentHandlers
with EmployeeEndpoints
with EmployeeHandlers
with PhoneEndpoints
with PhoneHandlers
with EmployeePhoneEndpoints
with EmployeePhoneHandlers:
val routes: Routes[
DepartmentService & EmployeeService & PhoneService & EmployeePhoneService,
Nothing
] = ...
val swaggerRoutes =
SwaggerUI.routes(
"docs",
OpenAPIGen.fromEndpoints(
createDepartment,
getDepartments,
getDepartmentById,
updateDepartment,
deleteDepartment,
createEmployee,
getEmployees,
getEmployeeById,
updateEmployee,
deleteEmployee,
createPhone,
getPhoneById,
updatePhone,
deletePhone,
addPhoneToEmployee,
retrieveEmployeePhones,
removePhoneFromEmployee
)
)
You can see that, to generate Swagger routes, you just need to call SwaggerUI.routes, where you provide:
We have almost everything we need to write the run method of our ZIO Application:
package com.example
import com.example.api.Router
import com.example.repository.*
import com.example.service.*
import zio.*
import zio.http.*
object Main extends ZIOAppDefault with Router:
val run =
Server
.serve(routes ++ swaggerRoutes)
.provide(
Server.default,
DepartmentServiceLive.layer,
DepartmentRepositoryLive.layer,
EmployeeServiceLive.layer,
EmployeeRepositoryLive.layer,
PhoneServiceLive.layer,
PhoneRepositoryLive.layer,
EmployeePhoneServiceLive.layer,
EmployeePhoneRepositoryLive.layer
)
So, to start a ZIO HTTP Server, we just need to call the Server.serve method, providing the Routes we want to serve (in this case routes and swaggerRoutes). After that, we just need to provide the ZLayers our application needs, including Server.default which runs the server with default configuration, at port 8080.
If we try to run the application we get a compilation error, saying that we need a ZLayer for Magnum’s Transactor, so we need to define that. Also, remember that I’ve mentioned above that we will be using Testcontainers for our PostgreSQL database, so we also need to define the logic for starting the DB container with the corresponding tables of our example, let’s do that now.
We will divide this task into smaller parts. First, let’s define add a ZIO effect in our Main object to start a PostgreSQLContainer using Testcontainers:
import org.testcontainers.containers.PostgreSQLContainer
val startPostgresContainer =
ZIO.fromAutoCloseable {
ZIO.attemptBlockingIO {
val container = PostgreSQLContainer("postgres:13.18-alpine3.20")
container.withDatabaseName("example")
container.withUsername("sa")
container.withPassword("sa")
container.start()
container
}
}
You can see this is very easy, we just need to define:
Next, because we will need a DataSource for instantiating a Magnum Transactor, let’s write a function that will create a HikariDataSource inside of a ZIO effect:
import com.zaxxer.hikari.{ HikariConfig, HikariDataSource }
def createDataSource(jdbcUrl: String, username: String, password: String) =
ZIO.fromAutoCloseable {
ZIO.attemptBlockingIO {
val config = HikariConfig()
config.setJdbcUrl(jdbcUrl)
config.setUsername(username)
config.setPassword(password)
HikariDataSource(config)
}
}
Now, based on startPostgresContainer and createDataSource, we can create a ZLayer that starts the PostgreSQL container and creates the corresponding DataSource:
val dataSourceLayer =
ZLayer.scoped {
for
postgresContainer <- startPostgresContainer
dataSource <- createDataSource(
postgresContainer.getJdbcUrl,
postgresContainer.getUsername,
postgresContainer.getPassword
)
yield dataSource
}
We will also need to create the database tables of our application on start, so let’s define a function for that purpose which uses Magnum:
import com.augustnagro.magnum.magzio.*
def createTables(xa: Transactor) =
xa.transact {
val departmentTable =
sql"""
CREATE TABLE ${tables.Department.table}(
${tables.Department.table.id} SERIAL NOT NULL,
${tables.Department.table.name} VARCHAR(50) NOT NULL,
PRIMARY KEY(${tables.Department.table.id})
)
"""
val employeeTable =
sql"""
CREATE TABLE ${tables.Employee.table}(
${tables.Employee.table.id} SERIAL NOT NULL,
${tables.Employee.table.name} VARCHAR(100) NOT NULL,
${tables.Employee.table.age} INT NOT NULL,
${tables.Employee.table.departmentId} INT NOT NULL,
PRIMARY KEY (${tables.Employee.table.id}),
FOREIGN KEY (${tables.Employee.table.departmentId})
REFERENCES ${tables.Department.table}(${tables.Department.table.id})
ON DELETE CASCADE
)
"""
val phoneTable =
sql"""
CREATE TABLE ${tables.Phone.table}(
${tables.Phone.table.id} SERIAL NOT NULL,
${tables.Phone.table.number} VARCHAR(15) NOT NULL,
PRIMARY KEY(${tables.Phone.table.id})
)
"""
val employeePhoneTable =
sql"""
CREATE TABLE ${tables.EmployeePhone.table}(
${tables.EmployeePhone.table.employeeId} INT NOT NULL,
${tables.EmployeePhone.table.phoneId} INT NOT NULL,
PRIMARY KEY (${tables.EmployeePhone.table.employeeId}, ${tables.EmployeePhone.table.phoneId}),
FOREIGN KEY (${tables.EmployeePhone.table.employeeId})
REFERENCES ${tables.Employee.table}(${tables.Employee.table.id})
ON DELETE CASCADE,
FOREIGN KEY (${tables.EmployeePhone.table.phoneId})
REFERENCES ${tables.Phone.table}(${tables.Phone.table.id})
ON DELETE CASCADE
)
"""
departmentTable.update.run()
employeeTable.update.run()
phoneTable.update.run()
employeePhoneTable.update.run()
}
You can see we have several custom SQL statements to create each table. To run them, you call the update method on each one, which returns an Update object, on which you can execute the run method, which expects an implicit DbCon which is provided by xa.transact.
Finally, we can combine everything together into a single ZLayer that starts the database, creates tables and returns the Transactor we need:
val dbLayer =
for
dataSource <- dataSourceLayer
xa <- Transactor.layer(dataSource.get)
_ <- ZLayer(createTables(xa.get))
yield xa
By the way, notice we are using the Transactor.layer function from Magnum. We are just providing a DataSource but it’s also possible to provide some configuration options, in this case we are using the default configuration.
Now we do have everything we need for our application’s run method, we just need to provide the missing dbLayer:
val run =
Server
.serve(routes ++ swaggerRoutes)
.provide(
Server.default,
DepartmentServiceLive.layer,
DepartmentRepositoryLive.layer,
EmployeeServiceLive.layer,
EmployeeRepositoryLive.layer,
PhoneServiceLive.layer,
PhoneRepositoryLive.layer,
EmployeePhoneServiceLive.layer,
EmployeePhoneRepositoryLive.layer,
dbLayer
)
We can enable request/response logging for our ZIO HTTP Routes very easily by using a Middleware:
val routes =
Routes(
createDepartment.implementHandler(handler(createDepartmentHandler)),
getDepartments.implementHandler(handler(getDepartmentsHandler)),
...
) @@ Middleware.requestLogging(logRequestBody = true, logResponseBody = true)
We also need to configure ZIO Logging for our application in the Main object, like this:
package com.example
import zio.*
import zio.logging.jul.bridge.JULBridge
import zio.logging.{ consoleLogger, ConsoleLoggerConfig, LogFilter, LogFormat }
import zio.logging.LoggerNameExtractor
object Main extends ZIOAppDefault with Router:
val logFormat =
LogFormat.label("name", LoggerNameExtractor.loggerNameAnnotationOrTrace.toLogFormat())
+ LogFormat.space
+ LogFormat.default
+ LogFormat.space
+ LogFormat.allAnnotations
val logFilterConfig =
LogFilter.LogLevelByNameConfig(
LogLevel.Info,
"com.augustnagro.magnum" -> LogLevel.Debug
)
override val bootstrap =
Runtime.removeDefaultLoggers
++ consoleLogger(ConsoleLoggerConfig(logFormat, logFilterConfig))
++ JULBridge.init(logFilterConfig.toFilter)
...
Let’s analyze what’s happening here:
Right now our application is fully functional, however we are not doing any data validations. So users can provide:
We could do some defensive programming to solve this problem. For instance, we could add some validation logic at the Handlers level for creating departments:
trait DepartmentHandlers:
def createDepartmentHandler(department: Department) =
ZIO
.serviceWithZIO[DepartmentService](_.create(department))
.when(department.name.nonEmpty && department.name.length <= 50)
.someOrElseZIO(
ZIO.dieMessage(
"Department's name should be non-empty and have a maximum length of 50"
)
)
So we are validating that the department’s name is not empty and has length <= 50 (that’s the maximum length we have defined for the corresponding database column). If valid, the underlying DepartmentService#create call gets executed with the given department.
This approach works but it has a problem though: if we look inside the DepartmentService#create code, how do we know the received department is valid? There’s no way to know if we look just at DepartmentService#create, because the department’s name still has a String type which can contain any string; so we need to go to other places of our codebase (in this case DepartmentHandlers.createDepartmentHandler) to check if some validation was done. And this same issue will be propagated to the repositories level at DepartmentRepository#create.
What we want is that, once the department’s name has been validated, its type should not be String anymore, but a different type like DepartmentName and accept that type in our services and repositories, so that:
And even better, validation should happen at the Endpoints level, such that even the Handlers receive valid data only.
So, let’s use Iron to implement this better approach. We can start by defining a specific type for department IDs:
package com.example.domain
import io.github.iltotore.iron.*
import io.github.iltotore.iron.constraint.all.*
type DepartmentIdDescription =
DescribedAs[Greater[0], "Department's ID should be strictly positive"]
type DepartmentId = Int :| DepartmentIdDescription
As you can see, to refine a type like Int we apply a type-level description to it, in this case DepartmentIdDescription, which contains:
Also an important detail is that Int :| DepartmentIdDescription is a type alias for IronType[Int, DepartmentIdDescription].
Now that we have DepartmentIdDescription, we can instantiate values for it in several different ways:
// Since 100 is known at compile-time, it gets automatically refined at compile-time too!
val departmentId1: DepartmentId = 100
// Since 0 is not a valid value for DepartmentId, we get a compilation error!
val departmentId2: DepartmentId = 0
// For runtime values, we can use .refine* extension methods
val rawDepartmentId: Int = ???
val departmentId3: Either[String, DepartmentId] =
rawDepartmentId.refineEither[DepartmentIdDescription]
val departmentId4: Option[DepartmentId] =
rawDepartmentId.refineOption[DepartmentIdDescription]
val departmentId5: DepartmentId =
rawDepartmentId.refineUnsafe[DepartmentIdDescription]
Also, Iron allows us to create a companion object for DepartmentId so that we can instantiate values in a nicer way:
object DepartmentId extends RefinedType[Int, DepartmentIdDescription]
And now we can use it like this:
// Since 100 is known at compile-time, it gets automatically refined at compile-time too!
val departmentId1 = DepartmentId(100)
// Since 0 is not a valid value for DepartmentId, we get a compilation error!
val departmentId2 = DepartmentId(0)
// Refining runtime values
val rawDepartmentId: Int = ???
val departmentId3 = DepartmentId.either(rawDepartmentId)
val departmentId4 = DepartmentId.option(rawDepartmentId)
val departmentId5: DepartmentId = DepartmentId.applyUnsafe(rawDepartmentId)
Now that we know how to use Iron, we can define some other types:
type DepartmentNameDescription =
DescribedAs[
Alphanumeric & Not[Empty] & MaxLength[50],
"Department's name should be alphanumeric, non-empty and have a maximum length of 50"
]
type DepartmentName = String :| DepartmentNameDescription
object DepartmentName extends RefinedType[String, DepartmentNameDescription]
type EmployeeIdDescription =
DescribedAs[Greater[0], "Employee's ID should be strictly positive"]
type EmployeeId = Int :| EmployeeIdDescription
object EmployeeId extends RefinedType[Int, EmployeeIdDescription]
type EmployeeNameDescription =
DescribedAs[
Alphanumeric & Not[Empty] & MaxLength[100],
"Employee's name should be alphanumeric, non-empty and have a maximum length of 100"
]
type EmployeeName = String :| EmployeeNameDescription
object EmployeeName extends RefinedType[String, EmployeeNameDescription]
type PhoneIdDescription =
DescribedAs[Greater[0], "Phone's ID should be strictly positive"]
type PhoneId = Int :| PhoneIdDescription
object PhoneId extends RefinedType[Int, PhoneIdDescription]
type PhoneNumberDescription =
DescribedAs[
ForAll[Digit] & MinLength[6] & MaxLength[15],
"Phone number should have a length between 6 and 15"
]
type PhoneNumber = String :| PhoneNumberDescription
object PhoneNumber extends RefinedType[String, PhoneNumberDescription]Finally, we can incorporate these new types into our domain models, like this:
final case class Department(name: DepartmentName) derives Schema
final case class Employee(name: EmployeeName, age: Age, departmentId: DepartmentId) derives Schema
final case class Phone(number: PhoneNumber) derives Schema
Thanks to this change, it is now impossible to instantiate invalid Departments, Employees or Phones, because their corresponding fields will always be valid!
There’s a problem though, which is that a Schema won’t be able to be automatically derived for our classes, since ZIO Schema does not know how to create a Schema for our new Iron types, so we have to do that by ourselves. Let’s define a generic given ironSchema in com.example.util.givens.scala:
package com.example.util
import io.github.iltotore.iron.*
import zio.schema.*
inline given ironSchema[T, Description](
using Schema[T], Constraint[T, Description]
): Schema[T :| Description] =
Schema[T].transformOrFail(_.refineEither[Description], Right(_))
Let’s analyze this:
Now, if we import this given into our domain model files, Schema will be derived successfully.
In order to ensure that only valid data is read/written from/to the database, we can use our new IronTypes in our Magnum entity classes instead of raw types. For example, let’s see how this looks for our Department entity (other entities will follow the same logic):
package com.example.tables
import com.augustnagro.magnum.magzio.*
import com.example.domain
import com.example.domain.{ DepartmentId, DepartmentName }
import io.github.iltotore.iron.*
@Table(PostgresDbType, SqlNameMapper.CamelToSnakeCase)
final case class Department(
@Id id: DepartmentId,
name: DepartmentName
) derives DbCodec:
val toDomain = domain.Department(name)
object Department:
val table = TableInfo[domain.Department, Department, DepartmentId]
def fromDomain(departmentId: DepartmentId, department: domain.Department): Department =
Department(departmentId, department.name)
The only problem now is that the automatic derivation of DbCodec will fail because Magnum does not know how to derive codecs for DepartmentId and DepartmentName. So, similarly to what we did in the previous section for deriving Schema, let’s define a generic given ironDbCodec in com.example.util.givens.scala:
package com.example.util
import com.augustnagro.magnum.DbCodec
import io.github.iltotore.iron.*
inline given ironDbCodec[T, Description](
using DbCodec[T], Constraint[T, Description]
): DbCodec[T :| Description] =
DbCodec[T].biMap(_.refineUnsafe[Description], identity)
Analyzing this we have:
Now, if we import this given into our entity files, DbCodec will be derived successfully.
We can also use our new IronTypes at the Repositories and Services level. Only methods’ signatures will change, but implementations will be the same. For instance, DepartmentRepository will look like this:
trait DepartmentRepository:
def create(department: Department): UIO[DepartmentId]
def retrieve(departmentId: DepartmentId): UIO[Option[Department]]
def retrieveByName(departmentName: DepartmentName): UIO[Option[Department]]
def retrieveAll: UIO[Vector[Department]]
def update(departmentId: DepartmentId, department: Department): UIO[Unit]
def delete(departmentId: DepartmentId): UIO[Unit]
And DepartmentService:
trait DepartmentService:
def create(department: Department): IO[DepartmentAlreadyExists, DepartmentId]
def retrieveAll: UIO[Vector[Department]]
def retrieveById(departmentId: DepartmentId): IO[DepartmentNotFound, Department]
def update(departmentId: DepartmentId, department: Department): IO[DepartmentNotFound, Unit]
def delete(departmentId: DepartmentId): UIO[Unit]
Other Repositories and Services follow the same logic.
We can start using our new IronTypes in our Endpoints, such that they work with valid domain types only. For instance, we have this in our DepartmentEndpoints trait:
trait DepartmentEndpoints:
val createDepartment =
Endpoint(Method.POST / "department")
.in[Department](Doc.p("Department to be created"))
.out[Int](Doc.p("ID of the created department"))
.outError[DepartmentAlreadyExists](Status.Conflict, Doc.p("The department already exists"))
?? Doc.p("Create a new department")
So, instead of defining the output type as Int, we can set it to DepartmentId instead; such that createDepartment can only return valid department IDs and not any integer!
trait DepartmentEndpoints:
val createDepartment =
Endpoint(Method.POST / "department")
.in[Department](Doc.p("Department to be created"))
.out[DepartmentId](Doc.p("ID of the created department"))
.outError[DepartmentAlreadyExists](Status.Conflict, Doc.p("The department already exists"))
?? Doc.p("Create a new department")
And now we will also need to change the corresponding Handler in the DepartmentHandlers trait so it returns a DepartmentId:
trait DepartmentHandlers:
def createDepartmentHandler(
department: Department
): ZIO[DepartmentService, DepartmentAlreadyExists, DepartmentId] =
ZIO.serviceWithZIO[DepartmentService](_.create(department))
We also have this other interesting Endpoint in the EmployeePhoneEndpoints trait:
trait EmployeePhoneEndpoints:
val addPhoneToEmployee =
Endpoint(Method.POST / "employee" / int("employeeId") / "phone" / int("phoneId"))
.out[Unit]
.outError[AppError](Status.NotFound, Doc.p("The employee/phone was not found"))
?? Doc.p("Add a phone to an employee")We want to change the Endpoint so that it only accepts valid EmployeeId and PhoneId, instead of any integer values. For that, we can define a custom idCodec in a Codecs trait, like this:
package com.example.api.endpoint
import io.github.iltotore.iron.*
import zio.http.*
import zio.http.codec.*
trait Codecs:
inline def idCodec[Description](
name: String = "id"
)(using Constraint[Int, Description]): PathCodec[Int :| Description] =
int(name).transformOrFail[Int :| Description](_.refineEither[Description])(Right(_))
What’s happening here is:
So now we can use idCodec in our addPhoneToEmployee Endpoint:
trait EmployeePhoneEndpoints extends Codecs:
val addPhoneToEmployee =
Endpoint {
Method.POST
/ "employee" / idCodec[EmployeeIdDescription]("employeeId")
/ "phone" / idCodec[PhoneIdDescription]("phoneId")
}
.out[Unit]
.outError[AppError](Status.NotFound, Doc.p("The employee/phone was not found"))
?? Doc.p("Add a phone to an employee")
We will also need to update the corresponding Handler. We had this:
trait EmployeePhoneHandlers:
def addPhoneToEmployeeHandler(
phoneId: Int,
employeeId: Int
): ZIO[EmployeePhoneService, AppError, Unit] =
ZIO.serviceWithZIO[EmployeePhoneService](_.addPhoneToEmployee(phoneId, employeeId))
And now we can use our IronTypes instead:
trait EmployeePhoneHandlers:
def addPhoneToEmployeeHandler(
phoneId: PhoneId,
employeeId: EmployeeId
): ZIO[EmployeePhoneService, AppError, Unit] =
ZIO.serviceWithZIO[EmployeePhoneService](_.addPhoneToEmployee(phoneId, employeeId))
However, if we try to compile we will get an error. The reason is because our addPhoneToEmployee Endpoint has a type:
Endpoint[(EmployeeId, PhoneId), (EmployeeId, PhoneId), AppError, Unit, None]
Which means it’s expecting EmployeeId first in the input and PhoneId second, but our addPhoneToEmployeeHandler has them in the reverse order! We hadn’t detected this issue before because originally both employeeId and phoneId were of type Int, so the compiler didn’t detect the problem. But now Iron came to the rescue because we have specific types for each ID! So the fix is simple:
trait EmployeePhoneHandlers:
def addPhoneToEmployeeHandler(
employeeId: EmployeeId,
phoneId: PhoneId
): ZIO[EmployeePhoneService, AppError, Unit] =
ZIO.serviceWithZIO[EmployeePhoneService](_.addPhoneToEmployee(phoneId, employeeId))
Finally we have to make similar changes for other Endpoints and Handlers, but I won’t include them here. You can take a look at the GitHub repo.
Now, thanks to Iron:
In this article we have seen a practical example of building a REST API in Scala 3 using ZIO HTTP, Magnum and Iron. Thanks to the ZIO HTTP Endpoints API we have been able not only to implement the server logic but also to generate OpenAPI documentation and serve it via SwaggerUI, all based on the same high-level descriptions provided by Endpoints.
We have been able to seamlessly integrate with a PostgreSQL database thanks to Magnum with its great ZIO module. It’s nice that the library offers auto-generated methods at compile time to deal with typical CRUD operations and at the same time gives us the flexibility to write our custom SQL queries thanks to its sql interpolator.
Finally, we have been able to improve type safety with Iron, which allowed us to introduce a boundary for our application, such that we don’t have to worry about dealing with invalid data in our application logic: illegal states become impossible to represent.
I hope you have found this article useful and that you are able to give these libraries a try by yourself so you can introduce them in your work or personal projects!
--
Get access to incredible functional programming talks, including some great ZIO ones at LambdaConf 2025 with this special discount.
Stay ahead with the latest insights and breakthroughs from the world of technology. Our newsletter delivers curated news, expert analysis, and exclusive updates right to your inbox. Join our community today and never miss out on what's next in tech.